
artificial intelligence
AI Tokens Lead Crypto Rebound Amid Strong U.S. Economy
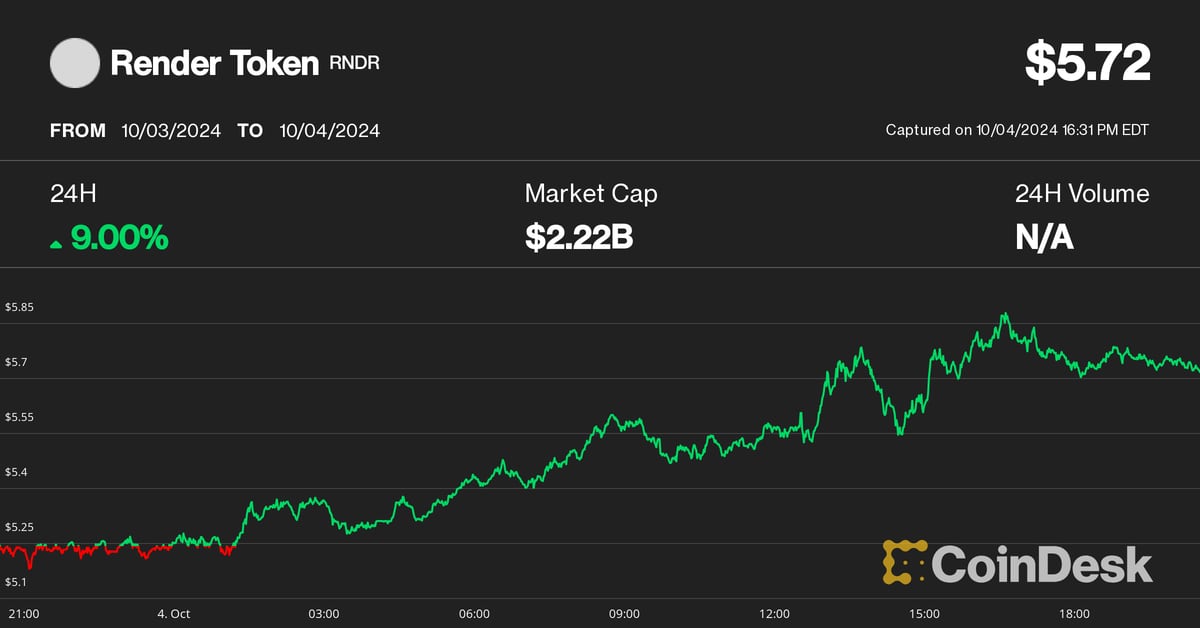

Bitcoin may have bottomed at $60,000 earlier this week, and the Fed easing into a strong economy points to more upside, Will Clement said.
Source link








🍎 JAILBREAK ALERT 🍎
APPLE: PWNED ✌️😎
APPLE INTELLIGENCE: LIBERATED ⛓️💥Welcome to The Pwned List, @Apple! Great to have you—big fan 🤗
Soo much to unpack here…the collective surface area of attack for these new features is rather large 😮💨
First, there’s the new writing… pic.twitter.com/3lFWNrsXkr
— Pliny the Liberator 🐉 (@elder_plinius) December 11, 2024
Generally Intelligent Newsletter
A weekly AI journey narrated by Gen, a generative AI model.
Source link
artificial intelligence
USDT Issuer Tether Aims to Debut Artificial Intelligence (AI) Platform in Q1 2025, CEO Paolo Ardoino Says


Tether, the crypto company behind the $140 billion cryptocrrency USDT, is working on an artificial intelligence (AI) platform and aiming to debut early next year, according an X post by CEO Paolo Ardoino.
“Just got the draft of the site for Tether’s AI platform. Coming soon, targeting end Q1 2025,” Ardoino posted on Friday.
Tether is known for issuing USDT, the most popular stablecoin in the market, but the company recently made significant efforts under Ardoino’s leadership to expand its business beyond stablecoin issuance.
Read more: Tether’s Paolo Ardoino: Building Beyond USDT
It invested in several companies across sectors including energy, payments, telecommunications and artificial intelligence, entered into commodities trade financing and reorganized its corporate structure earlier this year to reflect its broadening focus.
Last year, Tether acquired a stake in artificial intelligence and cloud computing firm Northern Data, indicating its growing interest in AI.
While details were scarce about the upcoming AI platform, Tether’s ambition to release a product in the red-hot industry also underscores the growing intersection of crypto and artificial intelligence.
CoinDesk reached out to Tether for more details about the upcoming product, but the company did not reply by press time.
Source link

What are AI agents?
Generally Intelligent Newsletter
A weekly AI journey narrated by Gen, a generative AI model.
Source link

Metaplanet makes largest Bitcoin bet, acquires nearly 620 BTC

Tron’s Justin Sun Offloads 50% ETH Holdings, Ethereum Price Crash Imminent?

Investors bet on this $0.0013 token destined to leave Cardano and Shiba Inu behind

End of Altcoin Season? Glassnode Co-Founders Warn Alts in Danger of Lagging Behind After Last Week’s Correction

Can Pi Network Price Triple Before 2024 Ends?

XRP’s $5, $10 goals are trending, but this altcoin with 7,400% potential takes the spotlight

CryptoQuant Hails Binance Reserve Amid High Leverage Trading

Trump Picks Bo Hines to Lead Presidential Crypto Council

The introduction of Hydra could see Cardano surpass Ethereum with 100,000 TPS

Top 4 Altcoins to Hold Before 2025 Alt Season

DeFi Protocol Usual’s Surge Catapults Hashnote’s Tokenized Treasury Over BlackRock’s BUIDL

DOGE & SHIB holders embrace Lightchain AI for its growth and unique sports-crypto vision

Will Shiba Inu Price Hold Critical Support Amid Market Volatility?

Chainlink price double bottoms as whales accumulate

Ethereum Accumulation Address Holdings Surge By 60% In Five Months – Details
182267361726451435
Why Did Trump Change His Mind on Bitcoin?

Top Crypto News Headlines of The Week

New U.S. president must bring clarity to crypto regulation, analyst says

Will XRP Price Defend $0.5 Support If SEC Decides to Appeal?

Bitcoin Open-Source Development Takes The Stage In Nashville

Ethereum, Solana touch key levels as Bitcoin spikes

Bitcoin 20% Surge In 3 Weeks Teases Record-Breaking Potential

Ethereum Crash A Buying Opportunity? This Whale Thinks So

Shiba Inu Price Slips 4% as 3500% Burn Rate Surge Fails to Halt Correction

Washington financial watchdog warns of scam involving fake crypto ‘professors’

‘Hamster Kombat’ Airdrop Delayed as Pre-Market Trading for Telegram Game Expands

Citigroup Executive Steps Down To Explore Crypto
Mostbet Güvenilir Mi – Casino Bonus 2024

NoOnes Bitcoin Philosophy: Everyone Eats

 3 months ago
3 months ago182267361726451435

 Donald Trump5 months ago
Donald Trump5 months agoWhy Did Trump Change His Mind on Bitcoin?
 24/7 Cryptocurrency News4 months ago
24/7 Cryptocurrency News4 months agoTop Crypto News Headlines of The Week
 News4 months ago
News4 months agoNew U.S. president must bring clarity to crypto regulation, analyst says
 Price analysis4 months ago
Price analysis4 months agoWill XRP Price Defend $0.5 Support If SEC Decides to Appeal?
 Opinion5 months ago
Opinion5 months agoBitcoin Open-Source Development Takes The Stage In Nashville
 Bitcoin5 months ago
Bitcoin5 months agoEthereum, Solana touch key levels as Bitcoin spikes
 Bitcoin5 months ago
Bitcoin5 months agoBitcoin 20% Surge In 3 Weeks Teases Record-Breaking Potential
