
technical
Early Bitcoin Developer Backs Satoshi Nakamoto Theory


Jeff Garzik, a veteran Linux contributor and early open-source developer who contributed to the Bitcoin project from 2010 to 2017, has released a series of new videos detailing his time working with Bitcoin’s anonymous inventor Satoshi Nakamoto.
Joining the project in July 2010, Garzik contributed to early software releases, entering notable pull requests including the first proposal to raise the block size limit, as well as the first proposal to eliminate subsidies for free transactions. Under Satoshi’s time as maintainer, Garzik had pull requests accepted, including for work separating the mining code from the Satoshi client.
Most notably, the new videos find Garzik sharing recollections about his time with Satoshi, including new commentary on whether Satoshi was indeed a singular individual or a group.
“Satoshi as a coder, he’s more the ‘A Beautiful Mind’ type lone genius,” Garzik recalls.
“When I was a computer science major, we thought highly of ourselves as coders, and we would notice that some of the other disciplines, the chemists, the biologists, the physicists, they had to do it, but they didn’t approach it as a profession. Satoshi was the same way.”
In this way, Garzik says he believes Satoshi knew what problem he wanted to solve, but that lacked an understanding of “modularity,” “unit testing,” and other basics that “computer science majors learn.”
“He very wisely pulled cryptographic solutions off the shelf that were well known, well studied, and he put all those together in a new and interesting way,” Garzik said, adding:
Elsewhere, Garzik attested to his belief that Satoshi was a “self-taught” programmer, arguing Bitcoin’s founder was humble about his limitations.
In other statements he spoke to Satoshi’s temperament and working methods, noting his strict focus on Bitcoin.
“Satoshi would never stray from that topic. He would never let slip any personal information whatsoever, never talk about his mood, the time of day,” he says in one clip. “It was always 100% all about Bitcoin.”
All told, the recollections cover a period of 6 months through Nakamoto’s resignation from the project in January 2011, at which point Garzik’s friend and collaborator Gavin Andresen took over as lead maintainer.
The videos come during a year in which other early Bitcoin contributors have gone public in releasing correspondence with Satoshi, with Martti ‘Sirius’ Malmi and Adam Back publishing hundreds of pages of never-before-seen emails in connection with a public trial in the U.K.
While Garzik has yet to release emails with Satoshi, the videos, produced by a new venture he founded, Hemi Network, represent the most public discussion the developer has had on the subject in some time.
Launched in July, the Hemi Network is advertised as “a modular Layer-2 protocol for superior scaling, security, and interoperability, powered by Bitcoin and Ethereum.”
The work follows a period after 2017 in which Garzik has become more interested in blockchain networks that are not tied to any specific base layer cryptocurrency, a path that includes Metronome, a project from 2017 that also sought compatibility with multiple blockchains.
Garzik left the Bitcoin project that year after serving as the lead maintainer for a hard fork of the Bitcoin protocol that despite early startup ecosystem support never formally launched.
The full video playlist can be accessed below:
Source link







Jeremy Rubin released a proposal two weeks ago titled Un’FE’d Covenants (FE = Functional Encryption). Given the ongoing debate over covenant proposals for Bitcoin the last year or two, his proposal marks a new practical option. All covenant proposals so far require a soft fork (actual opcodes), the development and implementation of unproven cryptography (Functional Encryption), or an absurdly high monetary cost to use (ColliderScript).
Jeremy’s proposal requires no softforks, and does not impose a burdensome and impractical cost on users to utilize. The trade off for that capability is a radically different security model. By using a system of oracles, and BitVM based bonds capable of slashing, covenants can be emulated on Bitcoin right now.
The Oracles
The first part of the scheme is obviously the oracles that enforce different covenant conditions. This is a relatively straightforward set up, and the first building block necessary for Jeremy’s proposal. The oracle has custody of the funds in this scheme, and is entrusted with the enforcement of the covenant conditions. You want the oracle to not have to locally keep track of the covenant conditions being enforced for each coin it custodies. This introduces state risk where if the oracles database is corrupted or lost it has no idea how to handle honest enforcement for everyone’s coins. In order to get around this problem, Jeremy makes use of Taproot.
Schnorr based keys can be “tweaked” by using the hash of data to modify a public key. This enables the tweaking of the corresponding private key to be able to sign for the modified key, as well as prove that whatever data was used to tweak the public key is committed to by that key. Having the oracle generate a key, and then the user tweaking that key with their covenant program allows a commitment to what the oracle is supposed to enforce while keeping the burden of storing that information on the user.
Oracles can also be federated in order to minimize the trust required in a single party to enforce things. From here, users can simply load the resulting address, and whenever they want to enforce the condition, approach the oracle(s) with the spending transaction, the oracle program, and the witness data necessary to prove that the transaction given to the oracle meets the conditions of the covenant. If the transaction is valid according to the covenant rules, the oracle signs it.
For any simple covenant where the outcomes are known ahead of time, such as CHECKTEMPLATEVERIFY (CTV), users can immediately have the oracle pre-sign the transactions enforcing the covenant and simply delay using them until necessary.
An important scenario to consider requiring extra functionality is state based covenants, such as rollups, that progress regularly and have an actual state (the current balance of users) to keep track of. In the case of such covenants, the transactions the oracle signs must commit to the current state of the covenant using OP_RETURN so that the oracle can efficiently verify each transaction updating the rollup or other system without having to download witness data for the entire history. This is to keep the oracle from having to store state locally themselves, which as noted above creates risks.
In the long term the data requirements of oracles can be optimized by using zero knowledge proofs, so that the oracle can simply verify a proof that the transaction they are being asked to sign follows the rules of the covenant without having to verify the raw witness data for larger more complex covenants. Again though, in the case of systems like rollups, care must be taken in designing them to guarantee that data required to exit the system is made available to users so they have it in their possession if they need to contact the oracle directly to reclaim their funds.
The BitVM Bond
So far the scheme is entirely trusted. You are essentially just giving someone else your money and hoping they can be trusted to enforce the conditions of arbitrary covenants. By modifying the scheme above slightly, this can be secured with a crypto-economic incentive rather than pure trust.
Above it was described how OP_RETURN is required to be used to track state for stateful covenants. OP_RETURN can also be used to publish the witness data of any covenant transactions to prove the conditions were correctly fulfilled.
A BitVM circuit can be constructed to verify whether a transaction signed by the oracle successfully matches the conditions of the covenant it is enforcing. Remember that the key itself that is generated and funds sent to commits to the conditions of any covenant being enforced. Meaning that data, as well as a transaction being spent from the address, can be fed into a BitVM instance.
Oracles can then be required to post a collateral bond with a BitVM operator (who must also post a bond for the Oracle to claim if they are falsely accused). This way, as long as the bond value is greater than the value secured in covenants by an oracle, the system can be securely used. There would be no way for an oracle to violate the conditions of a covenant they are enforcing without losing money in aggregate.
Trade Offs
There are clear trade offs here that are materially worse than simply implementing covenants in consensus rules. Firstly, the oracle must be online and reachable in order to make use of oracle enforced covenants. With the exception of pre-signed covenants such as CTV, if the oracle is offline when users need to enforce a covenant, they can’t. The oracle must be present to sign.
Secondly, the liquidity requirements for oracle bonds can become massive if the system was ever widely adopted. This makes it unbelievably inefficient compared to native implementation of covenant opcodes at the consensus level.
Lastly, the extra data required to be posted on-chain in order for the BitVM bond scheme to work is much less efficient with use of blockspace than native covenant implementations.
Overall, the proposal is nowhere near as efficient and secure as native covenants. On the other hand, if we do wind up in the worst case scenario of pre-mature ossification, this is a very workable way to shoehorn covenants into Bitcoin without depending on unproven cryptography or completely impractical costs imposed on end users.
Jeremy has given us a worst case scenario option to expand the design space of what can be built on Bitcoin.
Source link


If you’ve bought bitcoin, chances are that you want to self-custody. Without self-custody, you don’t really have bitcoin, so why wouldn’t you? Using a hardware device to set up an offline bitcoin wallet is generally recommended. But backing up your wallet is actually much more important than having a hardware wallet. Yet, bitcoin backups are often ignored as an afterthought.
We’ll now be looking into why backing up your bitcoin wallet is crucial, but more importantly how to properly do it with the right products to secure your bitcoin holdings for multiple generations without trusted third parties.
Backup First
If you don’t self-custody and rely on a trusted third party like an exchange, custodian or broker, you may have good reasons for this, but perhaps you would be better off thinking about holding your own keys. As the adage goes, not your keys, not your…
Now of course, if you only have $10 or $50 worth of bitcoin in self-custody, backing up your wallet may not be relevant at this time. But if, for example, you hold a month’s worth of salary, a year’s worth of savings or even more than 5% of your net worth, then a backup may be absolutely essential to secure your bitcoin holdings.
You should backup your bitcoin because electronics and hardware devices fail. That’s not specific to bitcoin or to openly criticize hardware wallet manufacturers. Rather, hardware wallets are similar to other general consumer electronics such as computers and USB keys, in that they break over time due to life hazards.
Having multiple keys within a multisig wallet may help reduce this risk of hardware failure, but is it enough for you to feel comfortable for the next 30 years? If not, read on. Paper backups are generally included when you buy a hardware wallet, but well, they’re paper. Paper is at risk of loss, shredding, misplacement, ink may fade, etc… Using paper for your backup is not a good idea. You should not store highly sensitive and perhaps incredibly valuable data onto paper for many years.
Medium of Storage
Over the years, and since Cryptosteel announced the world’s first metal backup back in 2013, we have seen many different formats of bitcoin metal backups by multiple different vendors. Which one is the preferred today? Is there any better format between cassettes, tiles, plates, punch cards and others?
First things first, make sure that your backup is built with high grade stainless steel, which is highly durable. Titanium options may also be a good alternative. Any other medium of storage used by existing manufacturers or recommended by free DIY options may be more fragile and prone to complete data loss in case of fire or other corrosive hazards (such as Aluminium).
Formats also exist in various options, such as flat cassettes with moving tiles, punching metal cards, ring tiles mounted onto a core, punchable tubes, punchable rings threaded onto a core, and more. So, which one is the best and why?
We need to establish the needs of someone who is backing their bitcoin seed phrase. The most important aspect is that it should be simple. Some would argue that’s not the priority but it really is. If it is difficult or inconvenient to use, then few people will do it right, while many others may be unable to complete a successful backup. Of course, a good bitcoin backup must be durable, recoverable, affordable and private, but that should almost be basic requirements for any product.
Anatomy of a Good Backup
We cannot start this discussion without sharing Lopp’s comprehensive technical overview of what makes a good seed phrase backup, based on his past research testing various models of metal bitcoin backups. The following analysis is more akin to an opinionated view of metal bitcoin backups as of 2024 focused on usability, security and durability.
A simple way to backup your bitcoin should require no extra tooling. That’s the best way to keep things simple for anyone looking to durably backup their bitcoin holdings. Requiring no tools is also safer with no risk of harm due to poor usage of tools. It’s also more discrete and enjoyable as there should be no noise from the process of making a backup. A larger number of people are able to backup their holdings if it does not require specialized equipment, such as sharp items, hammers, anvils or punches.
Obviously, your backup must be durable. That’s the whole point. We’ve established that stainless steel is the best alloy to rely on. But about the format? Over the years, we’ve seen different shapes of backups. What matters is that the format be resistant to life hazards, including fire, flood, tons of weight press and extreme changes in any of these conditions. We’re concerned about concrete life risks such as floods, hurricanes, as well as house and apartment fires, which can cause high temperatures but also buildings to crumble.
Options for backup formats usually fall within 6 categories to record data: sliding, stamping, engraving, etching, punching and stacking.
Sliding
Introduced in 2013 by Cryptosteel, the sliding backup design is a rail-based device in which you slide tiles, such as Cassette by Cryptosteel, Simbit or Billfodl. They are quite easy to set up, not requiring specialized tooling and are resistant to most risks such as corrosion from acid, heat from fire, and water floods. But this design may pose some risks of partial or even complete data loss if the medium gets bent or twisted by a very heavy weight press.
Vendor Reviews: Cryptosteel Cassette, Simbit, Ellipal Mnemonic Metal, Bunkeroid, HODL Wallet (discontinued), Billfodl (discontinued), Steeldisk (discontinued)
Engraving
Similar to stamping, engraving does not necessarily require stamps, but can be done with various sharp tools to permanently mark the metal, such as dremel, small chisels, and gravers. Of course, engraving can be done on many different formats of metal backups, but require even more specialized tools and security measures to avoid injuries than with stamping.
Vendor Reviews: SteelWallet (DIY), Steelki, CryptoVault (discontinued), Crypto Key Stack (discontinued)
Etching
Etching is used to mark metal backups with the corrosive action of an acid or electrochemical process. This is probably the least popular way to mark metal backups but is usually available as an option with vendors that rely on engraving for imprinting a backup in metal. It relies on highly specialized tools and is hazardous due to the dangerous chemical products required.
Vendor Reviews: Steelki, Black Seed Ink, Cryptoetch (discontinued), SteelWallet (DIY), CryptoVault (discontinued), Crypto Key Stack (discontinued)
Stamping
Usually the most widespread technique in both commercial and DIY products, stamping is a way to mark metal backups of different formats, from plates to hexagonal tubular shapes, fender washers and rings. Stamping requires medium to advanced technical skills, as it requires using tools, such as hammers, stamps and optional jig and guiding rails to ensure stamping is done safely with the correct alignment of characters. Wearing protective gears for eyes and fingers is usually recommended for safety.
Vendor Reviews: Coldbit, DIY BulletProof Bitcoin, Crypto Keys (discontinued), Hodlinox (discontinued), SAFU Ninja (DIY), Safe Seed, Seedor, Cryptotag
Punching
Similar to stamping, punching requires medium to advanced technical skills as special tools such as punches and hammers are used to mark metal permanently. It’s also quite popular as stamping, and requires only one single shape to punch, instead of multiple unique stamps. It’s usually done on metal plates with grids as well as hexagonal tubular shapes. It can be quite difficult to mark metal punching without making errors but also reading data may prove inconvenient for recovery. Wearing protective gears for eyes and fingers is usually recommended for safety.
Vendor Reviews: Blockplate, Seedplate, Smallseed, Attenuo (discontinued), Steelwallet, Coldkeys S, Bitplate Domino
Stacking
One of the least widespread commercial products, and perhaps most underappreciated formats is to stack tiles and other ring parts, such as fender washers. This design is compatible with beginners having low levels of technical skills, and DIY enthusiasts. The order and completeness of seed phrases is absolutely crucial for recovery, so this design must have reliable cotter-pins acting as closing and retention clips, or should include numbering for each word. Other than that, assembling these products does not require any tools, except for DIY options using the “stacking” design combined with “stamping”, for instance.
Vendor Reviews: Cryptosteel Capsule, Cryptosteel Seed12, SAFU Ninja DIY
Additional Considerations
Affordability
How much does a backup cost? The price at which a bitcoin backup product is available is an important criteria for many consumers. This is also true for hardware wallet manufacturers who may consider bundling their hardware devices with backup products. A price point under $50 is considered affordable. Anything over 100$ is considered premium, while the most common pricing is within the $50-100 range usually.
Erasability
Can errors be made and corrected without rendering the backup obsolete? Very few backup formats are editable and erasable. This can be useful for error correction, backup reuse with new seed phrases and also for educational content. It’s also a great benefit to discard a seed phrase backup privately, without leaking any sensitive information. Usually, the “stacking” model is the only compatible format to erase a backup.
Tamper-Evidence
Is it obvious if someone saw or made a copy of a backup? Revealing that a backup has been viewed by a third party is an important feature for anyone worried about the “evil maid attack”. Usually, tamper-evident seals are DIY and do not come built into the backup design. Very few backups have such seals integrated as part of the core product, though it is a useful privacy and security add-on.
Compactness
How small is a backup in size to hide it easily? The dimensions of a backup matter quite a lot to be able to hide it in some safe place, but also from a durability standpoint. A small and compact backup is less likely to bend to tons of weight pressure.
Seed12 as a Recommended Backup
Based on the previous discussion, our recommended bitcoin self-custody backup as of December 2024 is the Seed12 by Cryptosteel. Assemble your backup by threading character tiles onto the core, encasing them in an optional protective capsule and tamper-proof seal.
- Affordable: For $30, the Seed12 Core and $59 the Seed12 Security Kit are priced quite competitively to other commercial backups. Of course, DIY options remain more affordable for constrained budgets.
- Durable: Made from high grade stainless steel, Seed12 is highly resistant to impact, flood and fire temperatures.
- Compact: Packaged in a matchbox-sized case.
- No tools: This backup system requires no tools, such as hammers or sharp punches, making it easy and safe to set up.
- Erasable: As one of the smallest backup kits ever designed, it is also erasable and reusable, built with a modular tile system for easy error correction.
- Flexible: Consumers can purchase additional parts and only pay for what they use, such as extra tiles, capsules or tamper-proof seals.
The Right Conditions to Backup
Now that we’ve covered most aspects and considerations of what makes a good bitcoin backup, let’s briefly cover how and where to actually set it up. When setting up your bitcoin backup, ensure the following:
- Secure Environment: Choose a private, distraction-free space to set up your backup without risk of being overheard or observed.
- Backup Location: Store in a secure, fireproof, and waterproof location, such as a home safe or a safety deposit box for additional security.
- Redundancy: Create multiple backups and store them in geographically separated locations.
- Privacy Measures: Use tamper-evident seals or concealment techniques to detect or prevent unauthorized access.
- Documentation: Clearly label backups and write a documented plan to help yourself and your trusted ones to recover your bitcoin with your backups.
- Regular Checks: Periodically verify the backup’s condition and accessibility while ensuring it remains private and simple to use to recover your bitcoin.
If you have bitcoin in self-custody, you must have a good backup. Backing up your bitcoin is not just a precaution—it’s a necessity for securing your holdings over the long term. With the right materials, such as stainless steel or titanium, and careful attention to format, usability, and durability, you can ensure your backup withstands life’s challenges. Whether you opt for sliding, stamping, punching, or stacking designs, prioritize simplicity and reliability. By following proper setup conditions and choosing high-quality products built to last, you can protect your bitcoin for generations without relying on third parties.
This is a guest post by Thibaud. Opinions expressed are entirely their own and do not necessarily reflect those of BTC Inc or Bitcoin Magazine.
Source link


GingerWallet, the fork of WasabiWallet maintained by former zkSNACKs employees after the shut down of the Wasabi coinjoin coordinator, has received a vulnerability report from developer drkgry. This vulnerability would allow the total deanonymization of users inputs and outputs in a coinjoin round, giving a malicious coordinator the ability to completely undo any privacy gains from coinjoining by performing an active attack.
Wasabi 2.0 was a complete re-design of how Wasabi coordinated coinjoins, moving from the Zerolink framework utilizing fixed denomination mix amounts, to the Wabisabi protocol allowing dynamic multi-denomination amounts. This process involved switching from homogenous blinded tokens to register outputs to claim your coins back, to a dynamic credentials system called Keyed Verification Anonymous Credentials (KVACs). This would allow users to register blinded amounts that prevented theft of other users’ coins without revealing to the server plain-text amounts that could be correlated and prevent linking ownership of separate inputs.
When users begin participating in a round, they poll the coordinator server for information regarding the round. This returns a value in the RoundCreated parameters, called maxAmountCredentialValue. This is the highest value credential the server will issue. Each credential issuance is identifiable based on the value set here.
To save bandwidth, multiple proposed methods for clients to cross-verify this information were never implemented. This allows a malicious coordinator to give each user when they begin registering their inputs a unique maxAmountCredentialValue. In subsequent messages to the coordinator, including output registration, the coordinator could identify which user it was communicating with based on this value.
By “tagging” each user with a unique identifier in this way, a malicious coordinator can see which outputs are owned by which users, negating all privacy benefits they could have gained from coinjoining.
To my knowledge drkgry discovered this independently and disclosed it in good faith, but the members of the team who were present at zkSNACKs during the design phase of Wabisabi were absolutely aware of this issue.
“The second purpose of the round hash is to protect the clients from tagging attacks by the server, the credential issuer parameters must be identical for all credentials and other round metadata should be the same for all clients (e.g. to ensure that the server isn’t trying to influence clients to create some detectable bias in registrations).”
It was brought up in 2021 by Yuval Kogman, also known as nothingmuch, in 2021. Yuval was the developer to design what would become the Wabisabi protocol, and one of the designers in actually specifying the full protocol with István András Seres.
One final note is the tagging vulnerability is not actually addressed without this suggestion from Yuval as well as full ownership proofs bound to actual UTXOs as proposed in his original pull request discussing tagging attacks. All of the data being sent to clients isn’t bound to a specific round ID, so a malicious coordinator is still capable of pulling a similar attack by giving users unique round IDs and simply copying the necessary data and re-assigning each unique round ID per-user before sending any messages.
This is not the only outstanding vulnerability present in the current implementation of Wasabi 2.0 created by the rest of the team cutting corners during the implementation phase.
Source link
Solana beats Ethereum in a key metric 3 months in a row

SCENE’s 2024 Person of the Year: Iggy Azalea

BTC Risks Falling To $20K If This Happens

Most Layer 2 solutions are still struggling with scalability

Here’s why Stellar Price Could Go Parabolic Soon
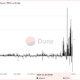
Perp-Focused HyperLiquid Experiences Record $60M in USDC Net Outflows

Experts say these 3 altcoins will rally 3,000% soon, and XRP isn’t one of them

Robert Kiyosaki Hints At Economic Depression Ahead, What It Means For BTC?

BNB Steadies Above Support: Will Bullish Momentum Return?

Metaplanet makes largest Bitcoin bet, acquires nearly 620 BTC

Tron’s Justin Sun Offloads 50% ETH Holdings, Ethereum Price Crash Imminent?

Investors bet on this $0.0013 token destined to leave Cardano and Shiba Inu behind

End of Altcoin Season? Glassnode Co-Founders Warn Alts in Danger of Lagging Behind After Last Week’s Correction

Can Pi Network Price Triple Before 2024 Ends?

XRP’s $5, $10 goals are trending, but this altcoin with 7,400% potential takes the spotlight
182267361726451435
Why Did Trump Change His Mind on Bitcoin?

Top Crypto News Headlines of The Week

New U.S. president must bring clarity to crypto regulation, analyst says

Will XRP Price Defend $0.5 Support If SEC Decides to Appeal?

Bitcoin Open-Source Development Takes The Stage In Nashville

Ethereum, Solana touch key levels as Bitcoin spikes

Bitcoin 20% Surge In 3 Weeks Teases Record-Breaking Potential

Ethereum Crash A Buying Opportunity? This Whale Thinks So

Shiba Inu Price Slips 4% as 3500% Burn Rate Surge Fails to Halt Correction

Washington financial watchdog warns of scam involving fake crypto ‘professors’

‘Hamster Kombat’ Airdrop Delayed as Pre-Market Trading for Telegram Game Expands

Citigroup Executive Steps Down To Explore Crypto
Mostbet Güvenilir Mi – Casino Bonus 2024

NoOnes Bitcoin Philosophy: Everyone Eats

 3 months ago
3 months ago182267361726451435

 Donald Trump5 months ago
Donald Trump5 months agoWhy Did Trump Change His Mind on Bitcoin?
 24/7 Cryptocurrency News4 months ago
24/7 Cryptocurrency News4 months agoTop Crypto News Headlines of The Week
 News4 months ago
News4 months agoNew U.S. president must bring clarity to crypto regulation, analyst says
 Price analysis4 months ago
Price analysis4 months agoWill XRP Price Defend $0.5 Support If SEC Decides to Appeal?
 Opinion5 months ago
Opinion5 months agoBitcoin Open-Source Development Takes The Stage In Nashville
 Bitcoin5 months ago
Bitcoin5 months agoEthereum, Solana touch key levels as Bitcoin spikes
 Bitcoin5 months ago
Bitcoin5 months agoBitcoin 20% Surge In 3 Weeks Teases Record-Breaking Potential
