
artificial intelligence
How To Create Hyper-Realistic AI Images with Stable Diffusion


The prompts
Stable Diffusion 1.5: the AI veteran that’s aging with grace
1. Juggernaut Rborn

2. Realistic Vision v5.1

3. I Can’t Believe It’s Not Photography

Honorable Mentions:



Stable Diffusion XL: The Versatile Visionaries
1. Juggernaut XL (Version x)

2. RealVisXL

3. HelloWorld XL v6.0


Pro tips for hyper-realistic images
Here are the resources we referenced in this guide:
Generally Intelligent Newsletter
A weekly AI journey narrated by Gen, a generative AI model.
Source link







My current views:
1. Superintelligent AI is very risky and we should not rush into it, and we should push against people who try. No $7T server farms plz.
2. A strong ecosystem of open models running on consumer hardware are an important hedge to protect against a future where…— vitalik.eth (@VitalikButerin) May 21, 2024
Generally Intelligent Newsletter
A weekly AI journey narrated by Gen, a generative AI model.
Source link
AGIX
Coinbase Won’t Support Upcoming AI Token Merger Between Fetch.ai, Ocean Protocol and SingularityNET

Top US exchange Coinbase is not going to facilitate the planned merger of multiple artificial intelligence altcoin projects into a single new crypto.
In an announcement via the social media platform X, Coinbase says that customers will have to initiate the merger on their own.
“Ocean (OCEAN) and Fetch.ai (FET) have announced a merger to form the Artificial Superintelligence Alliance (ASI). Coinbase will not execute the migration of these assets on behalf of users.”
In March, Fetch.ai (FET), Singularitynet (AGIX) and Ocean Protocol (OCEAN) announced a plan to merge with an aim to create the largest independent player in artificial intelligence (AI) research and development, which they are calling the Artificial Superintelligence Alliance (ASI).
The merger is happening in phases, beginning July 1st, according to a recent project update.
“Starting July 1, the token merger will temporarily consolidate SingularityNET’s AGIX and Ocean Protocol’s OCEAN tokens into Fetch.ai’s FET, before transitioning to the ASI ticker symbol at a later date. This update enables an efficient execution of the token merger, and outlines the timelines and crucial steps for token holders, ensuring a smooth and transparent process.”
Coinbase says users can effect the merger on their own using their wallets.
“Once the migration has launched, users will be able to migrate their OCEAN and FET to ASI using a self-custodial wallet, such as Coinbase Wallet. The ASI token merger will be compatible with all major software wallets.”
Don’t Miss a Beat – Subscribe to get email alerts delivered directly to your inbox
Check Price Action
Follow us on X, Facebook and Telegram
Surf The Daily Hodl Mix
 

Disclaimer: Opinions expressed at The Daily Hodl are not investment advice. Investors should do their due diligence before making any high-risk investments in Bitcoin, cryptocurrency or digital assets. Please be advised that your transfers and trades are at your own risk, and any losses you may incur are your responsibility. The Daily Hodl does not recommend the buying or selling of any cryptocurrencies or digital assets, nor is The Daily Hodl an investment advisor. Please note that The Daily Hodl participates in affiliate marketing.
Generated Image: Midjourney
Source link

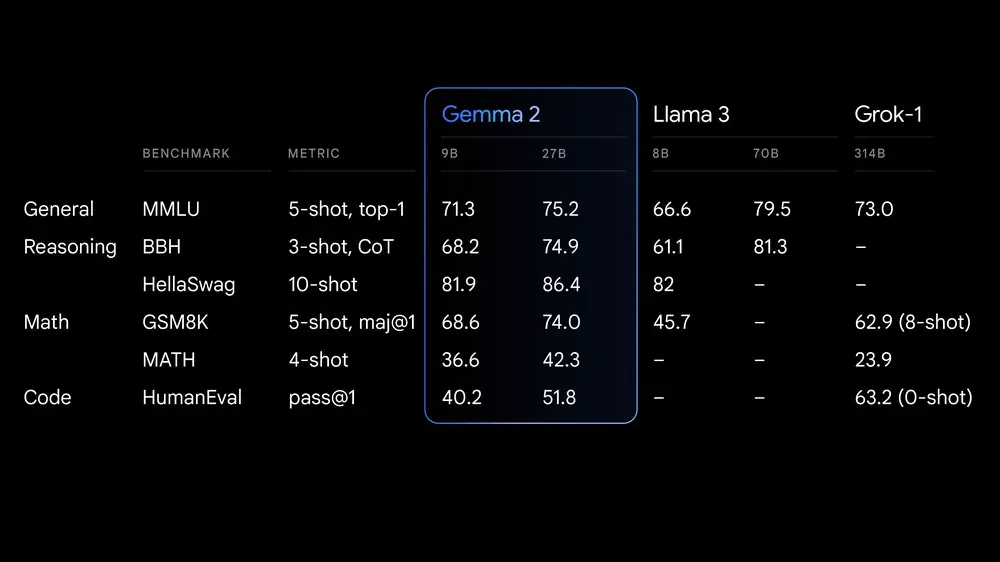
Gemma 2 Comes to Dominate the Open Source Space

Generally Intelligent Newsletter
A weekly AI journey narrated by Gen, a generative AI model.
Source link

The German Government Is Selling More Bitcoin – $28 Million Moves to Exchanges
BC.GAME Announces the Partnership with Leicester City and New $BC Token!

Justin Sun Says TRON Team Designing New Gas-Free Stablecoin Transfer Solution

Mt. Gox is a ‘thorn in Bitcoin’s side,’ analyst says

XRP Eyes Recovery Amid Massive Accumulation, What’s Next?

Germany Moves Another $28 Million in Bitcoin to Bitstamp, Coinbase

'Asia's MicroStrategy' Metaplanet Buys Another ¥400 Million Worth of Bitcoin

BlackRock’s BUIDL adds over $5m in a week despite market turbulence

Binance To Delist All Spot Pairs Of These Major Crypto

German Government Sill Holds 39,826 BTC, Blockchain Data Show

HIVE Digital stock rallies over 9% as Bitcoin miner bolsters crypto reserves to 2.5k BTC

Pepe Price Analysis Reveals Bullish Strength As Bitcoin Plummets

Taiwan is not in a CBDC rush as central bank lacks timetable

Will SHIB Price Reclaim $0.00003 Mark By July End?

The power of play: Web2 games need web3 stickiness

Bitcoin Dropped Below 2017 All-Time-High but Could Sellers be Getting Exhausted? – Blockchain News, Opinion, TV and Jobs

What does the Coinbase Premium Gap Tell us about Investor Activity? – Blockchain News, Opinion, TV and Jobs
BNM DAO Token Airdrop
A String of 200 ‘Sleeping Bitcoins’ From 2010 Worth $4.27 Million Moved on Friday

NFT Sector Keeps Developing – Number of Unique Ethereum NFT Traders Surged 276% in 2022 – Blockchain News, Opinion, TV and Jobs
New Minting Services

Block News Media Live Stream

SEC’s Chairman Gensler Takes Aggressive Stance on Tokens – Blockchain News, Opinion, TV and Jobs

Friends or Enemies? – Blockchain News, Opinion, TV and Jobs

Enjoy frictionless crypto purchases with Apple Pay and Google Pay | by Jim | @blockchain | Jun, 2022

How Web3 can prevent Hollywood strikes

Block News Media Live Stream

Block News Media Live Stream
Block News Media Live Stream

XRP Explodes With 1,300% Surge In Trading Volume As crypto Exchanges Jump On Board
 Altcoins2 years ago
Altcoins2 years agoBitcoin Dropped Below 2017 All-Time-High but Could Sellers be Getting Exhausted? – Blockchain News, Opinion, TV and Jobs
 Binance2 years ago
Binance2 years agoWhat does the Coinbase Premium Gap Tell us about Investor Activity? – Blockchain News, Opinion, TV and Jobs
- Uncategorized3 years ago
BNM DAO Token Airdrop

 Bitcoin miners2 years ago
Bitcoin miners2 years agoA String of 200 ‘Sleeping Bitcoins’ From 2010 Worth $4.27 Million Moved on Friday
 BTC1 year ago
BTC1 year agoNFT Sector Keeps Developing – Number of Unique Ethereum NFT Traders Surged 276% in 2022 – Blockchain News, Opinion, TV and Jobs
- Uncategorized3 years ago
New Minting Services
 Video2 years ago
Video2 years agoBlock News Media Live Stream
 Bitcoin1 year ago
Bitcoin1 year agoSEC’s Chairman Gensler Takes Aggressive Stance on Tokens – Blockchain News, Opinion, TV and Jobs
